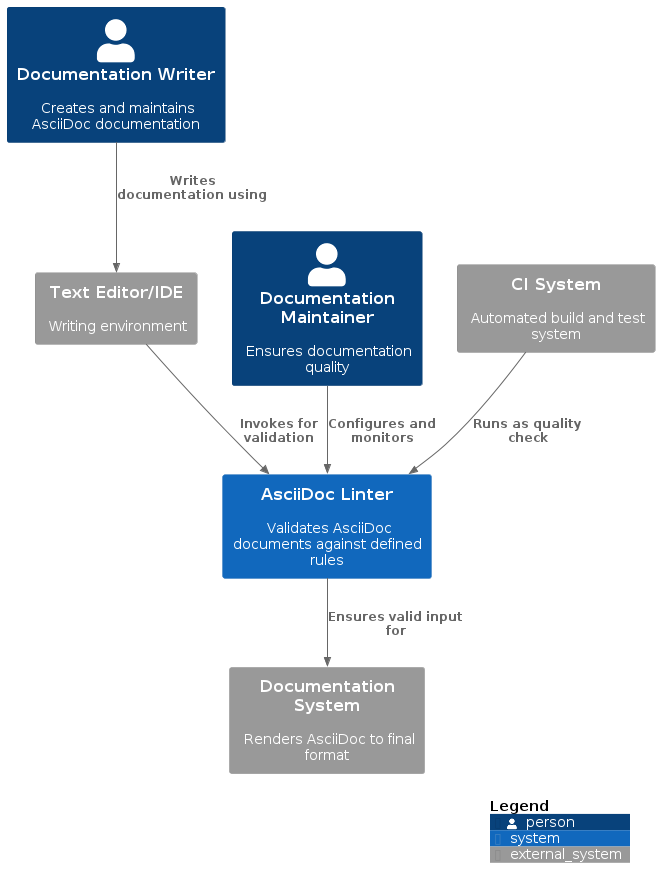
AsciiDoc Linter Architecture Documentation
Introduction and Goals
Requirements Overview
The AsciiDoc Linter is a tool designed to ensure consistent formatting and structure in AsciiDoc documents. It helps teams maintain high-quality documentation by enforcing style rules and best practices.
Key requirements include:
-
Validate AsciiDoc heading structure
-
Ensure consistent formatting
-
Provide clear error messages
-
Easy integration into existing workflows
-
Extensible rule system
Quality Goals
| Priority | Quality Goal | Motivation |
|---|---|---|
1 |
Extensibility |
The system must be easily extensible with new rules to accommodate different documentation standards and requirements. |
2 |
Reliability |
The linter must provide consistent and accurate results to maintain user trust. |
3 |
Usability |
Error messages must be clear and actionable, helping users fix documentation issues efficiently. |
4 |
Performance |
The linter should process documents quickly to maintain a smooth workflow. |
5 |
Maintainability |
The code must be well-structured and documented to facilitate future enhancements. |
Stakeholders
| Role/Name | Contact | Expectations |
|---|---|---|
Documentation Writers |
various |
* Clear error messages * Consistent results * Quick feedback |
Documentation Maintainers |
various |
* Configurable rules * Reliable validation * Integration with existing tools |
Development Team |
dev team |
* Extensible architecture * Good test coverage * Clear documentation |
Technical Writers |
various |
* Support for AsciiDoc best practices * Customizable rule sets * Batch processing capabilities |
Architecture Constraints
Technical Constraints
| Constraint | Description | Background |
|---|---|---|
Python 3.8+ |
The system must run on Python 3.8 or higher |
Need for modern language features and type hints |
Platform Independence |
Must run on Windows, Linux, and macOS |
Support for all major development platforms |
No External Dependencies |
Core functionality should work without external libraries |
Easy installation and deployment |
Memory Footprint |
Should process documents with minimal memory usage |
Support for large documentation projects |
Organizational Constraints
| Constraint | Description | Background |
|---|---|---|
Open Source |
Project must be open source under MIT license |
Community involvement and transparency |
Documentation |
All code must be documented with docstrings |
Maintainability and community contribution |
Test Coverage |
Minimum 90% test coverage required |
Quality assurance and reliability |
Version Control |
Git-based development with feature branches |
Collaborative development process |
Conventions
| Convention | Description | Background |
|---|---|---|
Code Style |
Follow PEP 8 guidelines |
Python community standards |
Type Hints |
Use type hints throughout the code |
Code clarity and IDE support |
Commit Messages |
Follow conventional commits specification |
Clear change history |
Documentation Format |
Use AsciiDoc for all documentation |
Dogfooding our own tool |
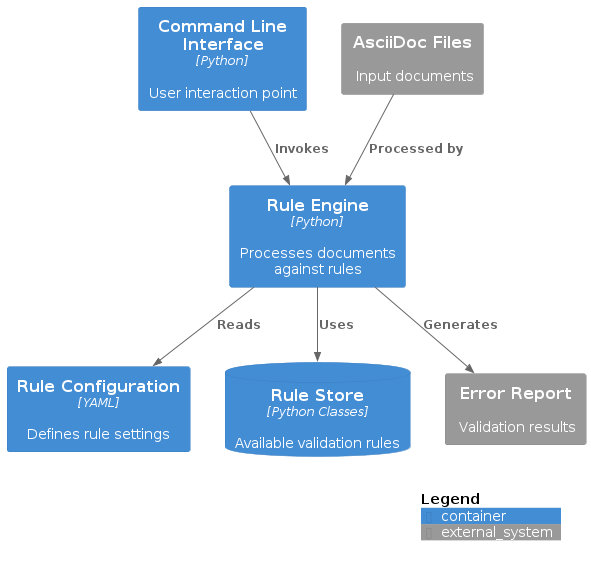
Solution Strategy
Quality Goals and Architectural Approaches
| Quality Goal | Solution Approach | Details |
|---|---|---|
Extensibility |
* Abstract base classes * Plugin architecture * Clear interfaces |
* New rules can be added by extending base classes * Plugin system allows external rule packages * Well-defined interfaces for rule implementation |
Reliability |
* Comprehensive testing * Strong typing * Defensive programming |
* High test coverage * Type hints throughout the code * Careful input validation |
Usability |
* Clear error messages * Context information * Configuration options |
* Detailed error descriptions * Line and column information * Configurable rule severity |
Performance |
* Efficient algorithms * Lazy loading * Caching |
* Line-by-line processing * Rules loaded on demand * Cache parsing results |
Maintainability |
* Clean architecture * SOLID principles * Documentation |
* Clear separation of concerns * Single responsibility principle * Comprehensive documentation |
Technology Decisions
| Technology | Decision | Rationale |
|---|---|---|
Python |
Primary implementation language |
* Strong standard library * Great text processing capabilities * Wide adoption in tooling |
Regular Expressions |
Pattern matching |
* Built into Python * Efficient for text processing * Well understood by developers |
YAML |
Configuration format |
* Human readable * Standard format * Good library support |
unittest |
Testing framework |
* Part of Python standard library * Well known to developers * Good IDE support |
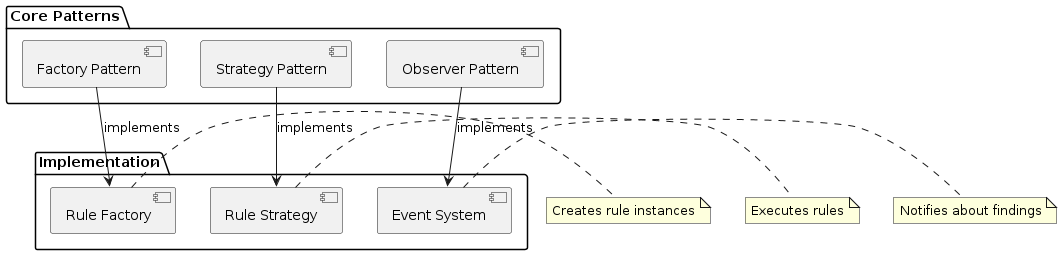
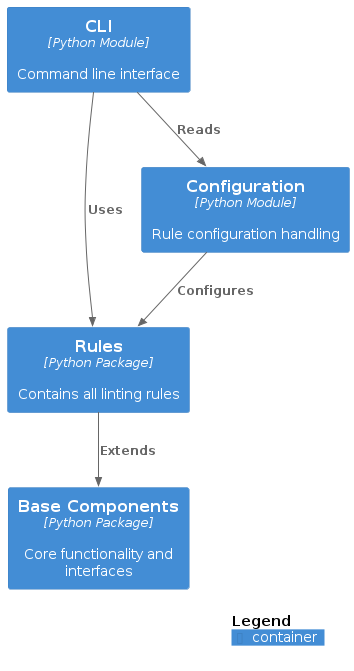
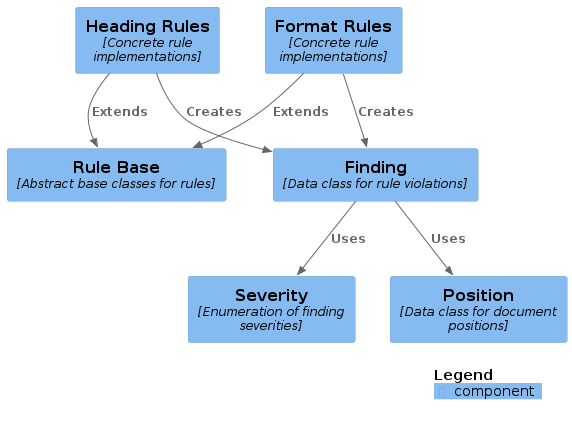
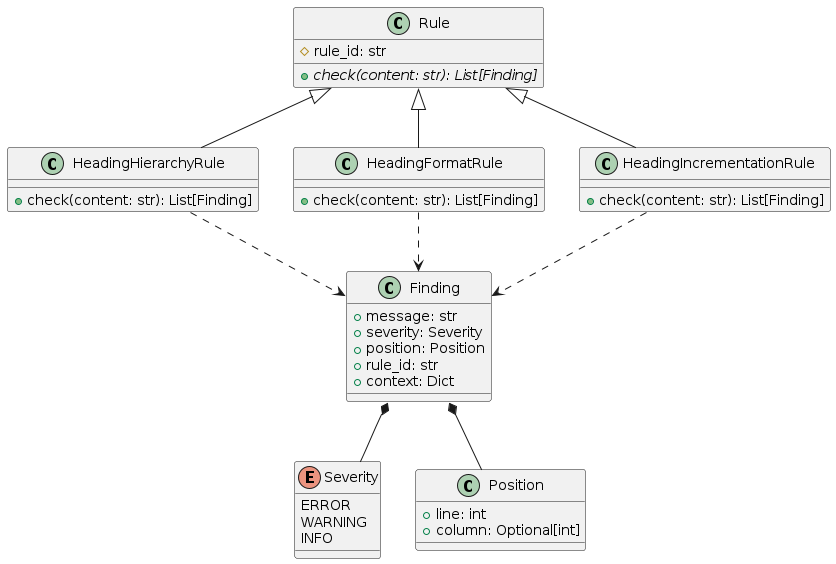
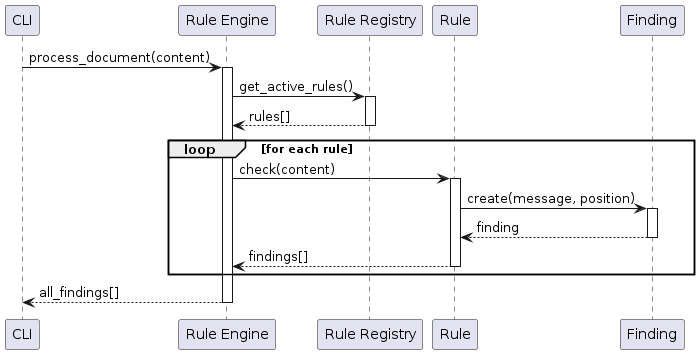
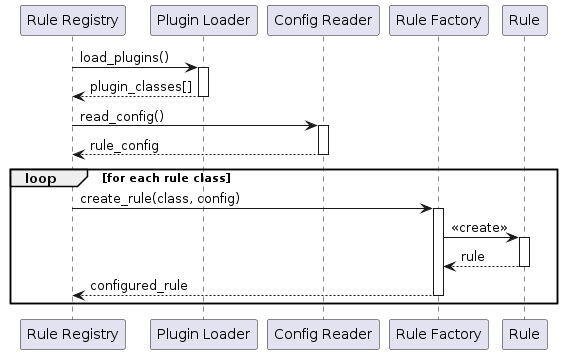
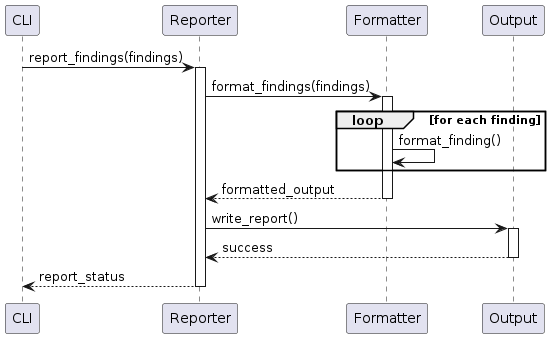
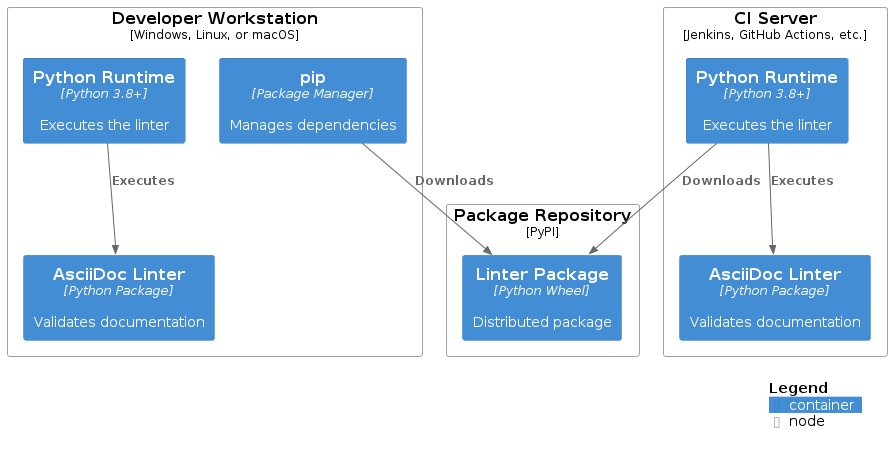
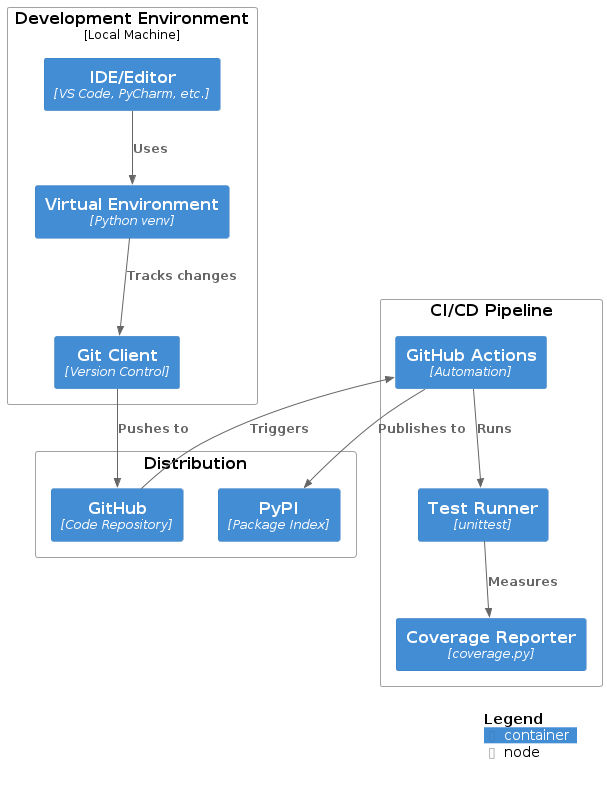
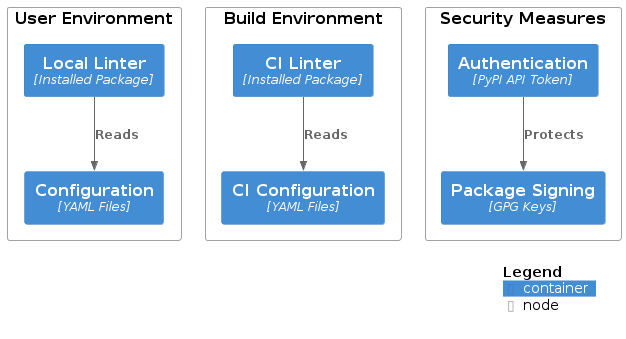
Cross-cutting Concepts
Security Concepts
Authentication and Authorization
-
Package distribution secured via PyPI authentication
-
Configuration files with restricted access
-
Signed releases with GPG keys
Input Validation
-
Strict content validation
-
Safe file handling
-
Memory usage limits
Output Sanitization
-
Escaped error messages
-
Safe file paths handling
-
Controlled error reporting
Configuration Concepts
Rule Configuration
rules:
heading_hierarchy:
enabled: true
severity: error
options:
max_level: 6
heading_format:
enabled: true
severity: warning
options:
require_space: true
require_capitalization: true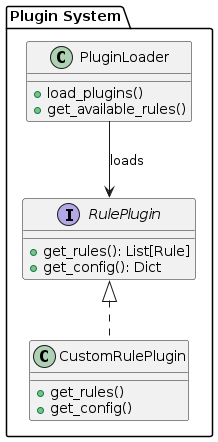
09_architecture_decisions.adoc - Architecture Decisions
Architecture Decisions
This chapter contains all architecture decisions for the AsciiDoc Linter project. Each decision is documented in a separate file and included here.
ADR 1: Rule Base Class Design
ADR-001-rule-base-class.adoc - Rule Base Class Design Decision
ADR 1: Rule Base Class Design
Status
Accepted
Context
We need a flexible and extensible way to implement different linting rules for AsciiDoc documents.
Decision
We will use an abstract base class Rule with a defined interface that all concrete rules must implement.
Consequences
-
Positive
-
Consistent interface for all rules
-
Easy to add new rules
-
Clear separation of concerns
-
Simplified testing through common interface
-
-
Negative
-
Additional abstraction layer
-
Slight performance overhead
-
ADR 2: Finding Data Structure
ADR-002-finding-data-structure.adoc - Finding Data Structure Decision
ADR 2: Finding Data Structure
Status
Accepted
Context
Rule violations need to be reported in a consistent and informative way.
Decision
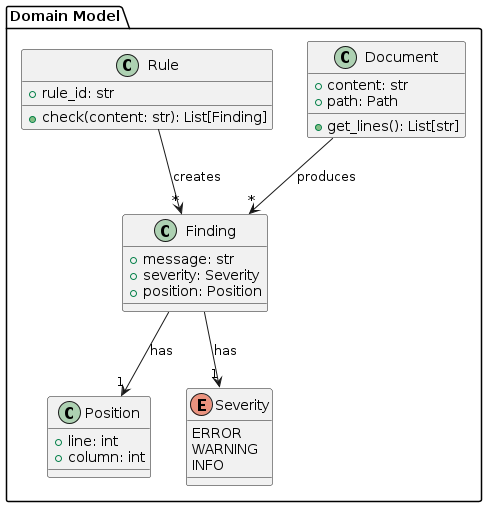
We will use a Finding data class with fields for message, severity, position, rule ID, and context.
Consequences
-
Positive
-
Structured error reporting
-
Rich context for violations
-
Consistent error format
-
-
Negative
-
More complex than simple string messages
-
Requires more memory for storing findings
-
ADR 3: Rule Implementation Strategy
ADR-003-rule-implementation-strategy.adoc - Rule Implementation Strategy Decision
ADR 3: Rule Implementation Strategy
Status
Accepted
Context
Rules need to process AsciiDoc content and identify violations efficiently.
Decision
Each rule will process the content line by line, using regular expressions for pattern matching.
Consequences
-
Positive
-
Simple implementation
-
Good performance for most cases
-
Easy to understand and maintain
-
-
Negative
-
Limited context awareness
-
May miss some complex patterns
-
Regular expressions can become complex
-
ADR 4: Test Strategy
ADR-004-test-strategy.adoc - Test Strategy Decision
ADR 4: Test Strategy
Status
Accepted
Context
Rules need to be thoroughly tested to ensure reliable operation.
Decision
Each rule will have its own test class with multiple test methods covering various scenarios.
Consequences
-
Positive
-
High test coverage
-
Clear test organization
-
Easy to add new test cases
-
-
Negative
-
More maintenance effort
-
Longer test execution time
-
ADR 5: Table Processing Strategy
ADR-005-table-processing-strategy.adoc - Table Processing Strategy Decision
ADR 5: Table Processing Strategy
Status
Proposed
Context
Table processing in AsciiDoc documents requires complex parsing and validation: * Tables can contain various content types (text, lists, blocks) * Cell extraction needs to handle multi-line content * Column counting must be reliable * List detection in cells must be accurate
Current implementation has issues: * Cell extraction produces incorrect results * List detection generates false positives * Column counting is unreliable
Decision
We will implement a new table processing strategy:
-
Two-Pass Parsing
-
First pass: Identify table boundaries and structure
-
Second pass: Extract and validate cell content
-
-
Cell Content Model
-
Create a dedicated TableCell class
-
Track content type (text, list, block)
-
Maintain line number information
-
-
List Detection
-
Use state machine for list recognition
-
Track list context across cell boundaries
-
Validate list markers against AsciiDoc spec
-
-
Column Management
-
Count columns based on header row
-
Validate all rows against header
-
Handle empty cells explicitly
-
Technical Details
class TableCell:
def __init__(self):
self.content = []
self.content_type = None
self.start_line = None
self.end_line = None
self.has_list = False
self.list_level = 0
class TableRow:
def __init__(self):
self.cells = []
self.line_number = None
self.is_header = False
class TableProcessor:
def first_pass(self, lines):
# Identify table structure
pass
def second_pass(self, table_lines):
# Extract cell content
pass
def detect_lists(self, cell):
# Use state machine for list detection
passConsequences
-
Positive
-
More accurate cell extraction
-
Reliable list detection
-
Better error reporting
-
Maintainable code structure
-
Clear separation of concerns
-
-
Negative
-
More complex implementation
-
Slightly higher memory usage
-
Additional processing overhead
-
More code to maintain
-
Implementation Plan
-
Phase 1: Core Structure
-
Implement TableCell and TableRow classes
-
Basic two-pass parsing
-
Unit tests for basic functionality
-
-
Phase 2: Content Processing
-
List detection state machine
-
Content type recognition
-
Error context collection
-
-
Phase 3: Validation
-
Column counting
-
Structure validation
-
Comprehensive test suite
-
Validation
Success criteria: * All current table-related tests pass * Cell extraction matches expected results * List detection has no false positives * Column counting is accurate * Memory usage remains within limits


ADR 6: Severity Standardization
ADR-006-severity-standardization.adoc - Severity Standardization Decision
ADR 6: Severity Standardization
Status
Proposed
Context
Current implementation has inconsistent severity level handling: * Mixed case usage (ERROR vs error) * Inconsistent severity levels across rules * No clear guidelines for severity assignment
Decision
We will standardize severity handling:
-
Severity Levels
-
ERROR: Issues that must be fixed
-
WARNING: Issues that should be reviewed
-
INFO: Suggestions for improvement
-
-
Implementation
-
Use lowercase for internal representation
-
Provide case-sensitive display methods
-
Add severity level documentation
-
-
Migration
-
Update all existing rules
-
Add validation in base class
-
Update tests to use new standard
-
Consequences
-
Positive
-
Consistent severity handling
-
Clear guidelines for new rules
-
Better user experience
-
-
Negative
-
Need to update existing code
-
Potential backward compatibility issues
-

ADR 7: Rule Registry Enhancement
ADR-007-rule-registry-enhancement.adoc - Rule Registry Enhancement Decision
ADR 7: Rule Registry Enhancement
Status
Proposed
Context
Current rule registry implementation lacks: * Test coverage * Clear registration mechanism * Version handling * Rule dependency management
Decision
We will enhance the rule registry:
-
Registration
-
Add explicit registration decorator
-
Support rule dependencies
-
Add version information
-
-
Management
-
Add rule enabling/disabling
-
Support rule groups
-
Add configuration validation
-
-
Testing
-
Add comprehensive test suite
-
Test all registration scenarios
-
Test configuration handling
-
Consequences
-
Positive
-
Better rule management
-
Clear registration process
-
Improved testability
-
-
Negative
-
More complex implementation
-
Additional maintenance overhead
-


10_quality_requirements.adoc - Quality Requirements
Quality Requirements
Quality Scenarios
Performance Scenarios
| Scenario | Stimulus | Response | Priority |
|---|---|---|---|
Fast Document Processing |
Process 1000-line document |
Complete in < 1 second |
High |
Multiple File Processing |
Process 100 documents |
Complete in < 10 seconds |
Medium |
Memory Usage |
Process large document (10MB) |
Use < 100MB RAM |
High |
Startup Time |
Launch linter |
Ready in < 0.5 seconds |
Medium |
Table Processing |
Process document with 100 tables |
Complete in < 2 seconds |
High |
Reliability Scenarios
| Scenario | Stimulus | Response | Priority |
|---|---|---|---|
Error Recovery |
Invalid input file |
Clear error message, continue with next file |
High |
Configuration Error |
Invalid rule configuration |
Detailed error message, use defaults |
High |
Plugin Failure |
Plugin crashes |
Isolate failure, continue with other rules |
Medium |
Resource Exhaustion |
System low on memory |
Graceful shutdown, save progress |
Medium |
Table Content Error |
Invalid table structure |
Clear error message with line numbers and context |
High |
List in Table |
Undeclared list in table cell |
Detect and report with context |
High |
Usability Scenarios
| Scenario | Stimulus | Response | Priority |
|---|---|---|---|
Clear Error Messages |
Rule violation found |
Show file, line, and actionable message |
High |
Configuration |
Change rule settings |
Take effect without restart |
Medium |
Integration |
Use in CI pipeline |
Exit code reflects success/failure |
High |
Documentation |
Look up rule details |
Find explanation within 30 seconds |
Medium |
Table Error Context |
Table formatting error |
Show table context and specific cell |
High |
Test Quality Scenarios
| Scenario | Stimulus | Response | Priority |
|---|---|---|---|
Test Coverage |
Add new feature |
Maintain >90% coverage |
High |
Test Success Rate |
Run test suite |
>95% tests passing |
High |
Edge Case Coverage |
Complex document structure |
All edge cases tested |
Medium |
Performance Tests |
Run benchmark suite |
Complete in < 5 minutes |
Medium |

Quality Metrics
Test Quality
-
Test Coverage: >90% for all modules
-
Test Success Rate: >95%
-
Edge Case Coverage: All identified edge cases have tests
Code Quality
-
Maintainability Index: >80
-
Cyclomatic Complexity: <10 per method
-
Documentation Coverage: >80%
Performance
-
Processing Speed: <1ms per line
-
Memory Usage: <100MB
-
Table Processing: <20ms per table
Reliability
-
False Positive Rate: <1%
-
Error Recovery: 100% of known error cases
-
Plugin Stability: No impact on core functionality :jbake-status: published :jbake-order: 11 :jbake-type: page_toc :jbake-menu: arc42 :jbake-title: Technical Risks and Technical Debt
11_technical_risks.adoc - Technical Risks
Technical Risks and Technical Debt
Current Issues (December 2024)
Test Failures
-
3 failed tests in table processing
-
Issues with cell extraction and list detection
-
Impact on table validation reliability
Coverage Gaps
-
rules.py: 0% coverage
-
reporter.py: 85% coverage
-
block_rules.py: 89% coverage
Implementation Issues
-
Inconsistent severity case handling
-
Missing rule_id attribute in base class
-
Table content validation problems
Risk Analysis
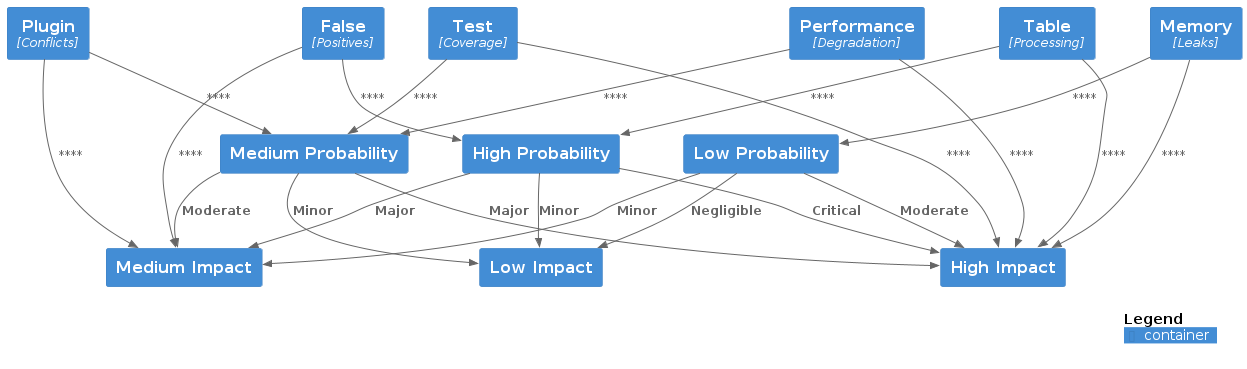
| Risk | Description | Impact | Probability | Mitigation |
|---|---|---|---|---|
Table Processing Errors |
Table content validation unreliable |
High |
High |
* Fix cell extraction * Improve list detection * Add comprehensive tests |
Test Coverage Gaps |
Critical modules lack tests |
High |
Medium |
* Add tests for rules.py * Improve reporter coverage * Document test scenarios |
Performance Degradation |
Rule processing becomes slow with many rules |
High |
Medium |
* Profile rule execution * Implement rule caching * Optimize core algorithms |
Memory Leaks |
Long-running processes accumulate memory |
High |
Low |
* Regular memory profiling * Automated testing * Resource cleanup |
False Positives |
Rules report incorrect violations |
Medium |
High |
* Extensive test cases * User feedback system * Rule configuration options |
Plugin Conflicts |
Custom rules interfere with core rules |
Medium |
Medium |
* Plugin isolation * Version compatibility checks * Clear plugin API |
Technical Debt
Current Technical Debt
| Area | Description | Impact | Priority |
|---|---|---|---|
Table Processing |
Cell extraction and list detection issues |
High |
High |
Test Coverage |
rules.py and reporter.py need tests |
High |
High |
Core Architecture |
Inconsistent severity handling |
Medium |
High |
Documentation |
Some advanced features poorly documented |
Medium |
Medium |
Error Handling |
Some error cases not specifically handled |
High |
High |
Configuration |
Hard-coded values that should be configurable |
Low |
Low |
Implementation Debt
| Component | Issue | Impact | Priority |
|---|---|---|---|
TableContentRule |
Cell extraction incorrect |
High |
High |
TableContentRule |
List detection problems |
High |
High |
Rule Base Class |
Missing rule_id attribute |
Medium |
High |
Severity Handling |
Inconsistent case usage |
Medium |
High |
rules.py |
No test coverage |
High |
High |

Mitigation Strategy
Phase 1: Critical Issues (1-2 weeks)
-
Fix table processing
-
Add missing tests
-
Standardize severity handling
Phase 2: Important Improvements (2-3 weeks)
-
Improve documentation
-
Enhance error handling
-
Add configuration options
Phase 3: Long-term Stability (3-4 weeks)
-
Performance optimization
-
Memory management
-
Plugin architecture improvements :jbake-status: published :jbake-order: 12 :jbake-type: page_toc :jbake-menu: arc42 :jbake-title: Glossary
Glossary
| Term | Definition | Additional Information |
|---|---|---|
AsciiDoc |
Lightweight markup language for documentation |
Similar to Markdown, but with more features for technical documentation |
Linter |
Tool that analyzes source code or text for potential errors |
Focuses on style, format, and structure issues |
Rule |
Individual check that validates specific aspects |
Can be enabled/disabled and configured |
Finding |
Result of a rule check indicating a potential issue |
Contains message, severity, and location information |
Severity |
Importance level of a finding |
ERROR, WARNING, or INFO |
Position |
Location in a document where an issue was found |
Contains line and optional column information |
Plugin |
Extension that adds additional functionality |
Can provide custom rules and configurations |
CI/CD |
Continuous Integration/Continuous Deployment |
Automated build, test, and deployment process |
PyPI |
Python Package Index |
Central repository for Python packages |
Virtual Environment |
Isolated Python runtime environment |
Manages project-specific dependencies |
Type Hints |
Python type annotations |
Helps with code understanding and static analysis |
Unit Test |
Test of individual components |
Ensures correct behavior of specific functions |
Integration Test |
Test of component interactions |
Verifies system behavior as a whole |
Coverage |
Measure of code tested by automated tests |
Usually expressed as percentage |
Technical Debt |
Development shortcuts that need future attention |
Balance between quick delivery and maintainability |
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.